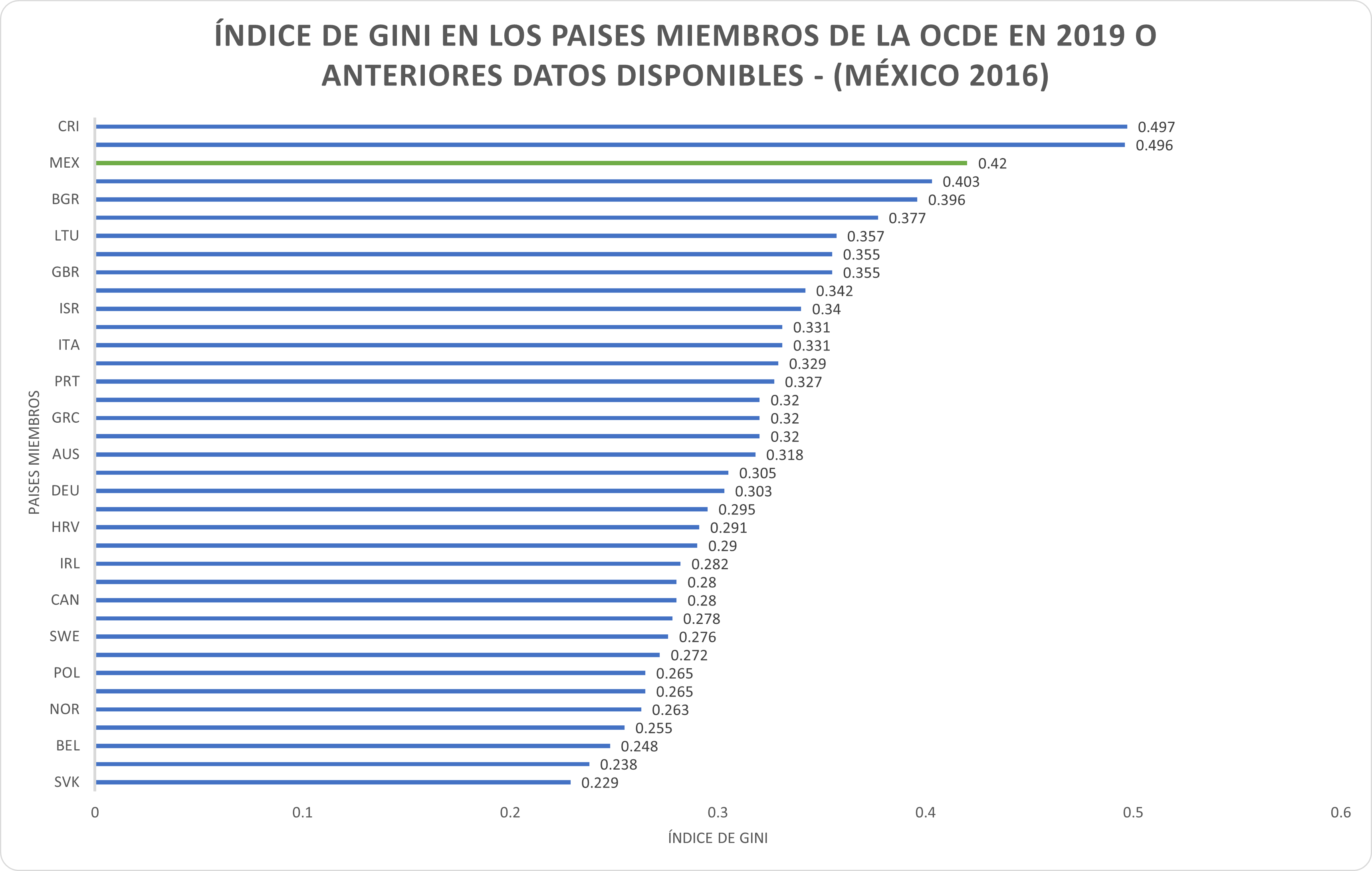
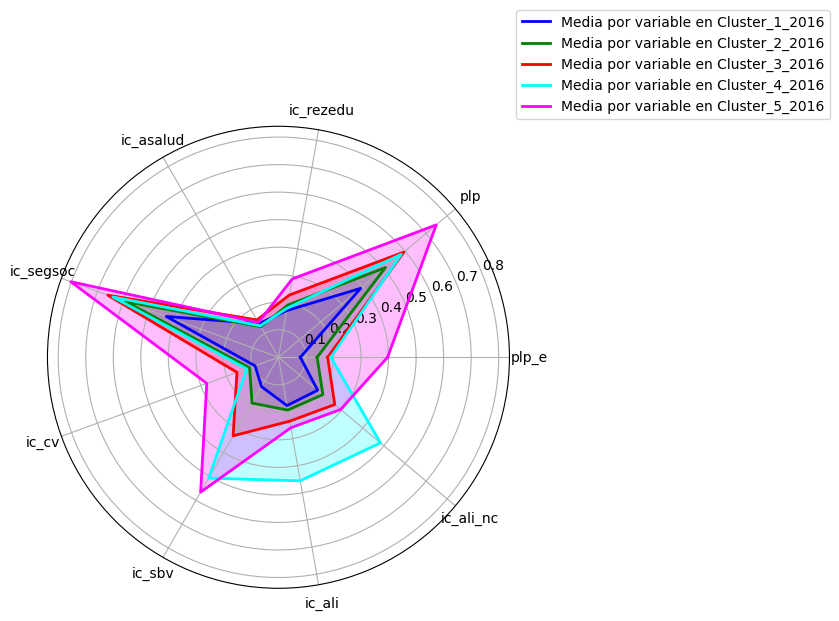
Analizando las estadísticas, se identifica que, de forma general, los indicadores de la pobreza multidimensional tuvieron una tendencia a la baja de 2016 a 2018, lo que se interpreta como una disminución de la pobreza multidimensional en dichos años. Desafortunadamente y a causa de la terrible situación de pandemia que sufrió nuestro país al igual que el resto del mundo en 2020, esta rompió con la tendencia, pues la mayoría de los indicadores no mostraron variaciones significativas, a excepción del ic_asalud, que evidentemente por la situación pandémica sufrió un alza que hizo pasar el promedio nacional de esta carencia de 14% en 2018 a 26% en 2020, un aumento del 12% lo cual es muy significativo.
En los gráficos, identificamos que en este periodo de 2016 a 2022, la estructura de los datos se ha mantenido prácticamente igual, sin mucha variación en sus distribuciones, y asociaciones lineales. A continuación, nos enfocarnos a describir un poco de esta estructura de datos.
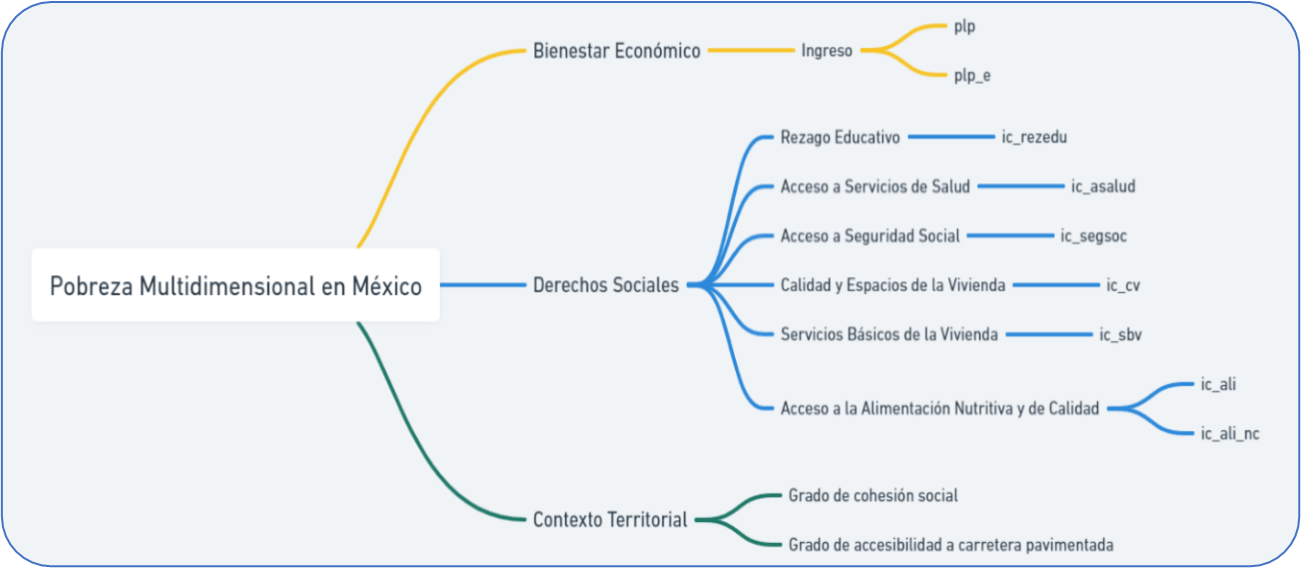
Se identifico que variables como plp_e, ic_rezedu, ic_asalud, ic_cv, ic_sbv, ic_ali y ic_ali_nc tienen distribuciones apuntaladas y sesgadas, cargadas a la izquierda, lo que indica que la mayoría de los estados tienen proporciones menores al 30% en estos indicadores. Encontramos distribuciones con un comportamiento distinto, como el de ic_segsoc que es mucho más normal, lo que apunta que a nivel nacional, la mayoría de los estados tiene una proporción de esta carencia en alrededor del 50%, con una desviación estándar del 14%. Otra distribución particular es la de plp, la cual es una distribución bimodal, que tiene dos medias, que en promedio se centran en un valor de 48-49% con una desviación estándar del 13%, cabe señalar también que la correlación entre ambas en los cuatro años es muy cercana al 0.90, lo indica que están altamente coleccionadas. Al igual que esta variable, existen más correlaciones importantes en el tiempo, como los es el caso de ic_segsoc y ic_cv y ic_sbv, que rondan entre el 0.90 y 0.80 respectivamente, lo que podría indicar de que aquellos que carecen de seguridad social, también carecen de servicios de vivienda y calidad de esta. ic_rezedu, también presenta una correlación cercana al 0.70 con ic_sbv, lo que también induce a la idea de que una parte de quienes carecen de servicios básicos de la vivienda, también tienen rezago educativo. Esta última también presenta una correlación estable en el tiempo con ic_ali en alrededor de 0.60, lo que lleva a la misma idea de que quienes padecen de servicios básicos de vivienda, también tiene carencia por alimentación, solo que en menor intensidad.
Una vez realizado el análisis estadístico descriptivo, procedemos a la parte inferencial. Para la metodología de regionalización, se implementan dos modelos de análisis de datos. El primero es un análisis Factorial de componentes principales, mientras es segundo es un análisis de clúster con las puntuaciones factoriales del análisis factorial.
Análisis Factorial
El Análisis Factorial, es un método de estadística multivariante, cuyo propósito es definir la estructura subyacente de una matriz de datos. Aborda el problema del análisis de las correlaciones entre un gran numero de variables con la definición de una serie de dimensiones subyacentes comunes, conocidas como factores. El análisis factorial permite identificar las dimensiones separadas de una estructura y posteriormente determinar el grado en el que se justifica cada variable por cada dimensión. Una vez determinadas estas dimensiones subyacentes, y la explicación de cada variable, se logran cosas: el resumen y la reducción de datos y dimensiones. (Hair, J. F.,1999)[13] Es decir, el análisis factorial permite obtener dimensiones subyacentes de una matriz de datos, que cuando son entendidas e interpretadas, permiten describir los datos con un numero menor de conceptos que las variables individuales originales. Se puede obtener esta reducción de datos al calcular las puntuaciones factoriales para cada dimensión subyacente y sustituir estas por las variables originales.
Para obtener las puntuaciones factoriales se necesita de la matriz de cargas, esta matriz muestra la relación entre cada variable observada y los factores subyacentes o no observados identificados durante el análisis. Cada elemento de esta matriz representa la carga factorial, que es el coeficiente que indica cuánto de la varianza en una variable observada es explicada por un factor.
Es decir, la matriz de cargas dice que tan fuertemente asociada esta cada variable observada con cada factor. Lo que permite interpretar las puntuaciones factoriales, al saber el peso de todas las variables observadas en los factores latentes no observados.
Existen distintos métodos para estimar la matriz de cargas, en este caso, se implementa el análisis Factorial de componentes principales, que está basado en la descomposición espectral de la matriz de correlaciones, a través de los valores y vectores propios, y transformaciones a partir de los mismos. Dada la extencion de dicha estimacion de la matriz de cargas, esta no se presentara detalladamente aqui. Sin emabargo puede consultarse en la version completa del articulo de investigacion.
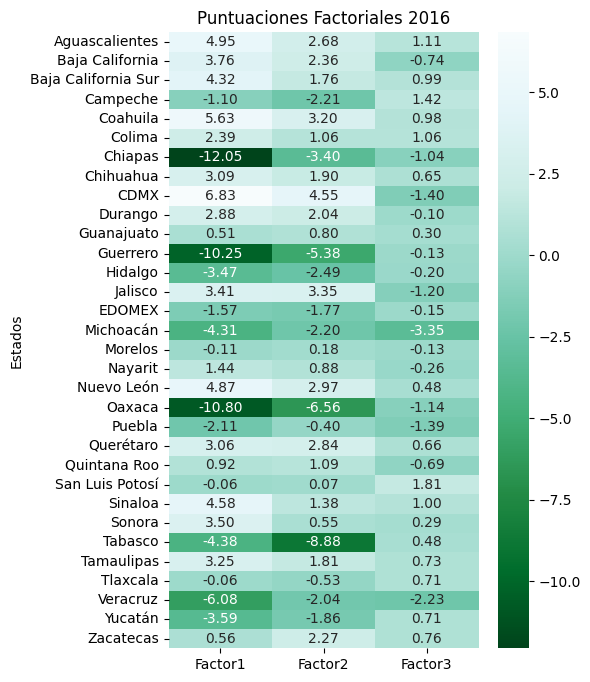
Aqui, siemplemente mostraremos la matriz de cargas para 2016 (LM16 = Loading Matrix 16) obtenidad tras la estimacion, la cual se presenta a continuacion.
La coloración de la matriz proporciona una representación visual de la fuerza y de las asociaciones y los pesos de los factores: los tonos más oscuros indican las cargas más fuertes, mientras que los mas claros, son la mas débiles.
Se identifican asociaciones muy importantes de plp_e, plp, ic_rezedu,ic_segsoc, ic_cv, ic_sbv en el primer factor; ic_ali y ic_ali_nc en el segundo; y de ic_asalud en el tercero.
Las cargas factoriales tiene mayormente signo negativo, lo que implica que al calcular las puntuaciones factoriales (que son el producto punto de los vectores fila de la matriz original estandarizada por el vector columna de la matriz de cargas respectiva a cada factor) estas se interpretaran de la siguiente forma:
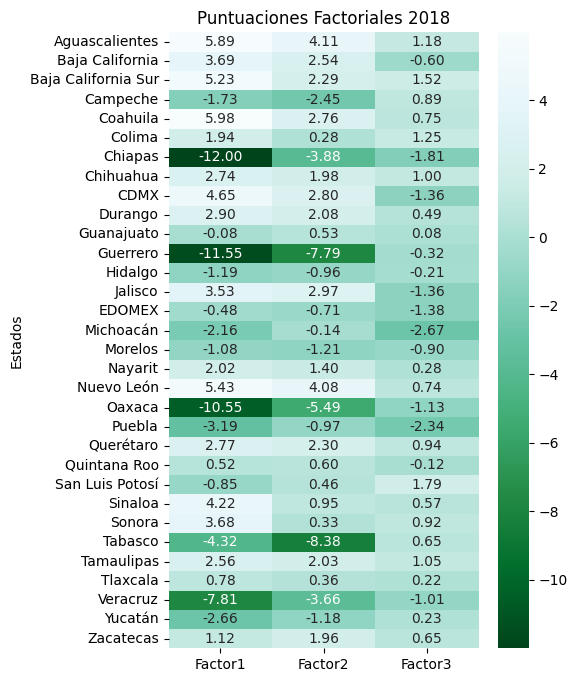
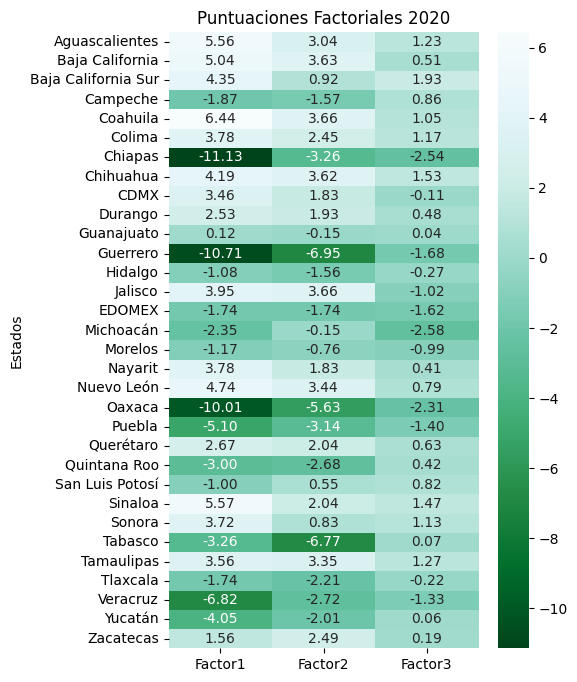
A mayor valor en las variables originales, mas negativa será la puntuación de estas en los tres factores, indicando así, que los estados con puntuaciones más pequeñas (más negativas) serán los que mayor presencia de pobreza multidimensional presentan. Mientras que los de mayores puntuaciones (menos negativas) serán los menos afectados. Es decir, mientras mas negativa sea una puntuación factorial, más pobre multidimensionalmente será el respectivo estado en el respectivo factor.
Gracias a el análisis factorial, las puntuaciones factoriales pueden interpretarse como un rango de la pobreza multidimensional, ya que al ser el producto punto de los vectores fila de la matriz original y los vectores columna de la matriz de cargas; las puntuaciones factoriales son combinaciones lineales de todas las variables reflejos de la multidimensionalidad de la pobreza estipulada en la LGDS y su Art.36.
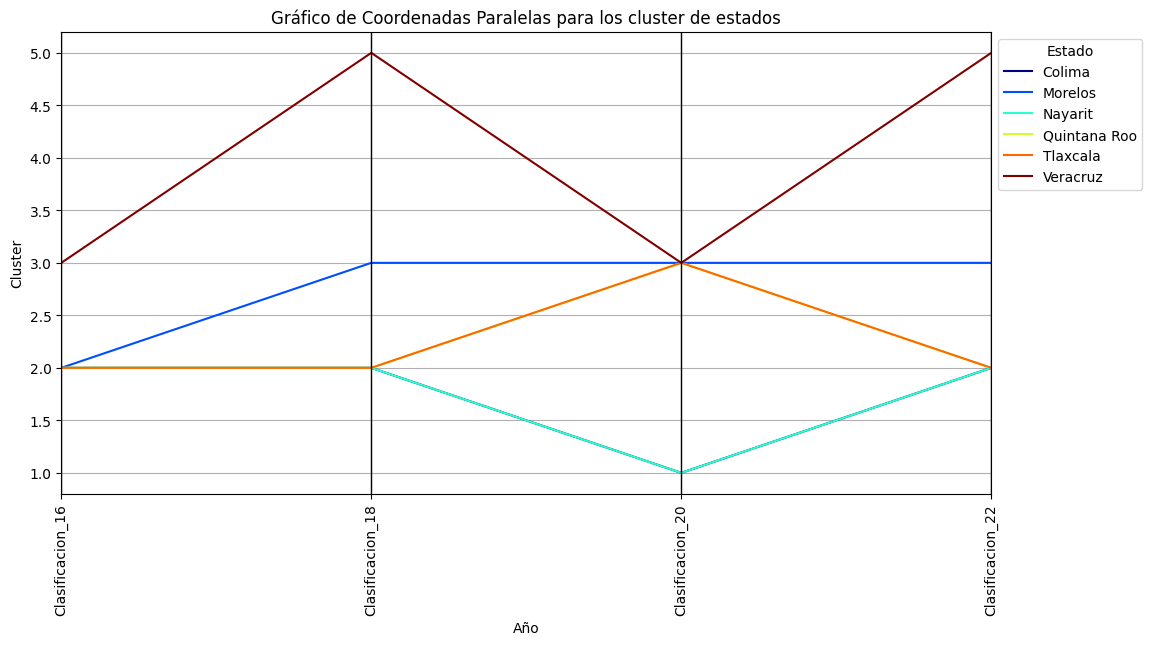
Utilizando la matriz de cargas de 2016, se calculan las puntuaciones factoriales para 2018, 2020, y 2022, esto con la finalidad, de que las puntuaciones sean comparables entre sí.
Las puntuaciones factoriales para cada año, se presentan a continuación: